
嗯...今天要來聊聊「資料」這件事。
感覺好像很硬,但其實它演化的過程蠻有趣的。不是突然蹦一聲就變成我們現在說的「大數據」或「AI」,而是一步一步,為了解決眼前的麻煩,才慢慢長成今天這個樣子。
有句話說得蠻好的,雖然有點諷刺:「每個複雜的問題,都有一個簡單、直接、易懂...但錯誤的答案。」我覺得用來看資料的發展史,再適合不過了。我們總是在找那個「當下最好」的解法,但這個解法,往往又會變成下一個時代要解決的新問題。
這整個故事,其實就是一部不斷「取捨」的歷史。
一切的開始:從記帳到資料庫
最早的時候,電腦還不是家家戶戶都有的東西。所謂的「資料」,可能就是公司記錄員工幾點上班、薪水發了沒、今天賣掉多少東西... 這種「交易」紀錄。很單純,一筆一筆記下來。
當這些紀錄開始數位化,就出現了資料庫,還有一個聽起來很專業的詞叫 OLTP(線上交易處理)。簡單講,就是專門應付這種一筆一筆、快速新增或修改的系統。你去超商買東西,店員「嗶」一下,背後就是這種系統在跑。
這時候,有個叫 Codd 的天才,提出了「關聯式模型」... 這東西真的很關鍵,統治了江湖幾十年。他的核心思想叫「正規化」(Normalization)。你不用管技術細節,它的精神就是:每樣東西都好好分類,放在它該在的格子裡,而且只放一次,不重複。 這樣資料才不會亂七八糟,也比較省空間。
聽起來很完美,對吧?嗯,在當時是。但問題來了...
老闆們開始想:「我能不能用這些資料,來預測下個月的業績?看看哪個廣告有效?」
這下麻煩了。OLTP 系統就像個忙著結帳的店員,你一直跑去問他一堆分析性的問題,他會崩潰。他的設計就不是拿來做大量計算和統計的。於是,為了解決這個問題,「資料倉儲」(Data Warehousing,DWH)就誕生了。人們開始把交易系統的資料,另外複製一份,專門丟到這個「倉庫」裡,讓分析師們在裡面盡情地玩,不會影響到第一線的結帳作業。也因此出現了一個新的職業:資料工程師 (Data Engineer),專門做這個搬運和整理資料的苦力活。
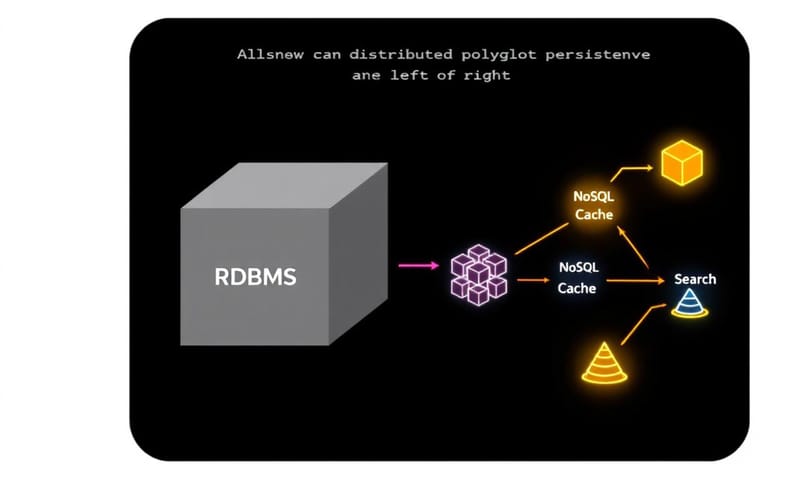
網路來了,資料庫撐不住了?
然後,網路時代來了。轟!全世界的人都連上線,資料量根本是用炸的。網站開得快不快,變成生死存亡的關鍵。你慢個一秒,客人就跑去對手家了。
lecturing a bit, but it's important.這時候,那個曾經完美的「關聯式資料庫」,開始有點...力不從心。它什麼都想管好,要確保每一筆資料都乾乾淨淨、規規矩矩,但在需要極高速度、和應付千奇百怪資料格式(比如使用者的留言、點擊紀錄、圖片)的場景下,這種「潔癖」反而成了包袱。
所以,NoSQL 資料庫就出現了。NoSQL 的意思不是「不要 SQL」,比較像是「不只用 SQL」(Not Only SQL)。它的核心精神就是「針對特定問題,用最適合的工具」。不用再堅持所有資料都得塞進一個完美的表格裡。這帶來了一個新概念,叫做「多樣化持續儲存」(Polyglot Persistence),白話文就是:我們家廚房裡,可以同時有炒菜鍋、電鍋、還有烤箱,看今天要煮什麼菜,就用哪個鍋。
聽起來很棒,對吧?但... 你懂的,天下沒有白吃的午餐。 trade-offs, always trade-offs.
怎麼選?看你要解決什麼問題
老實說,到現在還是很多人搞不清楚這幾個東西的差別。我弄了個簡單的比較表,用比較口語的方式說,希望能幫你理解那個「取捨」到底是什麼。
| 類型 | 最適合幹嘛? | 優點(爽在哪) | 缺點(痛點) |
|---|---|---|---|
| 關聯式資料庫 (Relational) | 要確保資料絕對正確、一致性的地方。像銀行的帳務系統、電商的訂單管理。 | 資料乾淨、結構清楚。交易過程很穩,不容易出錯(ACID 特性)。 | 彈性比較差。想加個欄位或改個結構,有時候跟搬家一樣麻煩。人一多、資料一雜,速度就可能慢下來。 |
| NoSQL 資料庫 | 需要速度快、資料量超大、格式又不固定的地方。比如社群網站的動態、IoT 設備的感測數據。 | 速度快,資料隨便塞都行。要加幾台機器來分擔工作量(擴展)也相對簡單。 | 資料一致性通常比較弱。你剛發的文,你朋友可能要過幾秒才看到。管理起來也比較...野。 |
| 資料倉儲 (DWH) | 專門給分析師、數據科學家做深度分析、跑報表用的。把各路資料匯集起來做大事的地方。 | 為了分析而生的!跑那種複雜、耗時的查詢,速度比直接查交易系統快多了。 | 它不是即時的。裡面的資料可能是昨天、甚至上週的。而且蓋一個倉儲...嗯,真的很花錢花時間。 |
系統變複雜了,然後呢?
semicolon feels a bit formal, but let's keep it.用了各種鍋子之後,你的廚房就變成了「分散式系統」。東西不再放在一個籃子裡,而是散落在各處。好處是快、有彈性、不容易一次全掛掉。壞處是...管理起來根本是惡夢。
你得確保A鍋的資料,能順利流到B鍋;你得監控每個鍋子有沒有好好工作;萬一其中一個壞了,要怎麼讓整套系統還能動?
這時候,Google 他們家搞 SRE (網站可靠性工程) 的那套方法論,就被借來用在資料庫上,變成了 DBRE (資料庫可靠性工程)。這群人的工作,就是在確保這堆複雜的系統健健康康、跑得順、而且死不了。
說到這個,我就想到... 在台灣,很多中小企業可能沒有資源搞一個專門的 DBRE 團隊。現實情況常常是,那個最懂電腦的倒楣鬼,一个人要扛起所有事。這跟 Google 那種有完整體系的做法,真的是很不一樣的風景。沒有對錯,就是資源和規模的差異。
再來,當你的資料流這麼複雜時,另一個問題就浮上檯面了:「我怎麼知道這些資料是對的?」這就是「資料可觀測性」(Data Observability) 的概念。它就像食材的品管,確保你從農場(來源系統)收來的菜(資料),在經過清洗、烹煮(轉換)之後,端上餐桌(給AI模型或分析師)時,還是新鮮、沒壞掉的。
從算命到 AI,還有那個叫「治理」的大魔王
有了這麼多資料,又有人整理好,我們自然就想拿來做更酷的事,像是預測、甚至是讓機器自己學習,也就是我們現在常聽到的機器學習 (ML) 跟人工智慧 (AI)。
這不新鮮,幾千年前埃及人就看著尼羅河氾濫的紀錄來預測週期。但現在,我們有的是天文數字般的資料和運算能力。不過,當生成式 AI 出現後,大家開始緊張了...這些資料到底流去哪?安不安全?我的個人隱私呢?
這就帶出了最後,也是現在最頭痛的大魔王:「資料治理」(Data Governance)。
如果說資料是「新的石油」,那資料治理,就是決定誰可以開採、誰來蓋加油站、油價怎麼訂、還有廢油要怎麼處理的一整套規則。
尤其當大家把系統都搬上雲端(Cloud-Native),雖然省了買機器的錢(資本支出變營運支出),但也代表你的資料可能放在別人家的電腦裡。這時候,資料的主權是誰的?要遵守哪個國家的法規?誰有權限看?誰該為資料外洩負責?這些問題,現在每個公司都躲不掉。

所以你看,從最開始單純的記帳,到現在搞得這麼複雜,其實整個過程就是一部不斷「發現問題、解決問題、然後製造新問題」的循環史。沒有什麼技術是永遠的王者,每一步都是在各種條件下的權衡取捨。
了解這段路,或許能幫助我們在面對下一個技術浪潮時,看得更清楚一點。畢竟,太陽底下沒有新鮮事,變的只是工具,不變的...永遠是那些關於成本、效率、安全性和複雜度之間的拉扯。
你覺得你的公司或團隊,目前在哪個階段呢?
A) 還在跟 Excel 奮鬥。
B) 有資料庫,但分析跟交易都混在一起,常常卡住。
C) 已經有資料倉儲,但正煩惱資料品質跟更新速度。
D) 已經上了雲端,開始頭痛治理和安全性的問題。
歡迎在下面留言分享你的「痛」在哪裡。😂



