
先說結論
OK,爬蟲程式。今天來聊這個。簡單講,它就是一個可以自動上網抓資料的機器人程式。 你可以把它想像成一個超級勤勞的圖書館小助理,你給他一份書單(就是網址清單),他就會自動跑去圖書館的每個角落,把書(網頁內容)的目錄(索引)抄回來,或是直接把書的內容整本影印(抓取)回來。 整個過程都是自動的,這就是為什麼大家這麼愛用它,省下超多人工複製貼上的時間。
爬蟲到底在幹嘛?看幾個例子就懂了
好,理論很無聊,直接看例子。你每天都在用,只是你不知道而已。
- 搜尋引擎:這應該最好懂。Google、Bing 這些,它們背後就是超大型的爬蟲軍團,不停地在全世界的網站上爬來爬去,把網頁抓回去建立索引。 這樣你搜尋關鍵字時,它才能秒速回你一堆相關網站。
- 比價網站:想買機票、訂飯店?這些網站會派出爬蟲去各大航空公司跟訂房網,把最新的價格抓回來,讓你不用一家一家比。
- 輿情分析與市場研究:企業想知道網友對自家產品的評價,或是競爭對手的動態,就可以用爬蟲去抓 PTT、Dcard、新聞網站的相關文章跟留言回來分析。
- AI 模型訓練:最近很紅的 AI,像是 ChatGPT,它們需要讀超大量的文字資料來學習怎麼「說話」。這些資料很多也是靠爬蟲從網路上收集來的。
那...爬蟲是怎麼動的?
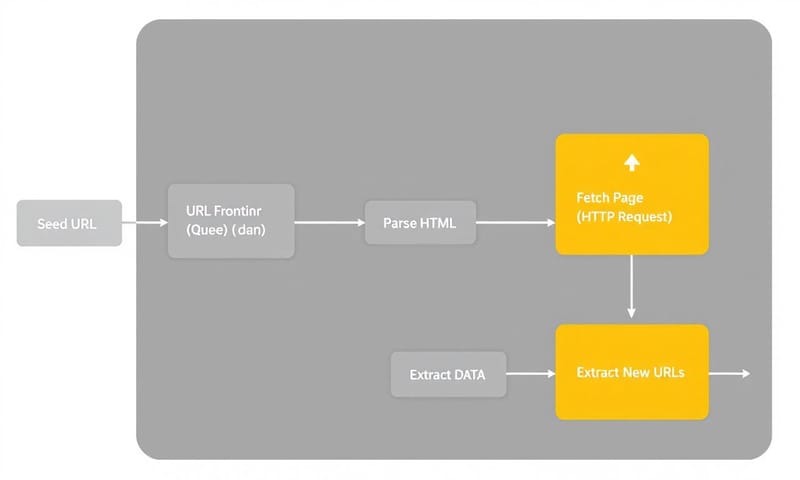
OK,所以這個小助理(爬蟲)到底是怎麼工作的?其實原理不複雜,大致上就幾個步驟:
- 給他一個起點 (Seed URLs):你得先給爬蟲一或多個起始網址,就像跟助理說:「先從這幾個書架開始找」。
- 發出請求 (Request):爬蟲會像你的瀏覽器一樣,對目標網址發出一個「我想看這個頁面」的請求。 伺服器收到請求後,會把網頁的原始碼(通常是 HTML)回傳給爬蟲。
- 解析與擷取 (Parse & Extract):爬蟲拿到 HTML 原始碼後,這堆東西對人來說根本沒法看。所以它會用特定的工具去解析,從中找到你想要的資料,比如商品價格、新聞標題等等。
- 找出新連結並重複:在解析的過程中,爬蟲也會找出這個頁面上的其他超連結,把這些新的網址放回「待辦清單」(URL Frontier)裡,然後再回去第二步,繼續抓下一個網址,一直重複下去,直到沒有新網址或你叫它停為止。
對,就是這麼一個樸實無華的循環。但魔鬼藏在細節裡。
開發前必知的 5 個基礎概念
在你自己想寫一個,或請別人寫之前,這幾個觀念一定要先弄懂,不然很容易踩坑。
1. 爬蟲 (Crawling) vs. 爬取 (Scraping)
這兩個詞常被混用,但其實不一樣。簡單說:
- 爬蟲 (Crawling):重點在「廣泛地探索與索引」。像 Google 那樣,目標是跑遍整個網站,知道網站上有哪些頁面。過程比較像在畫地圖。
- 爬取/抓取 (Scraping):重點在「精準地擷取資料」。目標很明確,就是要從特定頁面拿走特定資訊,比如股價、商品規格等。 這是大多數商業應用的真正目的。
所以,爬行是過程,抓取是目的。通常會先爬行找到目標頁面,然後再對那個頁面進行抓取。
2. 網站的說明書:robots.txt
你可以把 `robots.txt` 想像成是網站管理員貼在門口的一張「訪客須知」。 這個文字檔會放在網站的根目錄下,裡面寫明了希望爬蟲遵守的規則,比如「這個資料夾的內容請不要爬」、「爬取的速度請慢一點」等等。 大部分的「好」爬蟲(像 Googlebot)都會遵守這個君子協定。但它沒有法律強制力,壞爬蟲可以完全不理它。
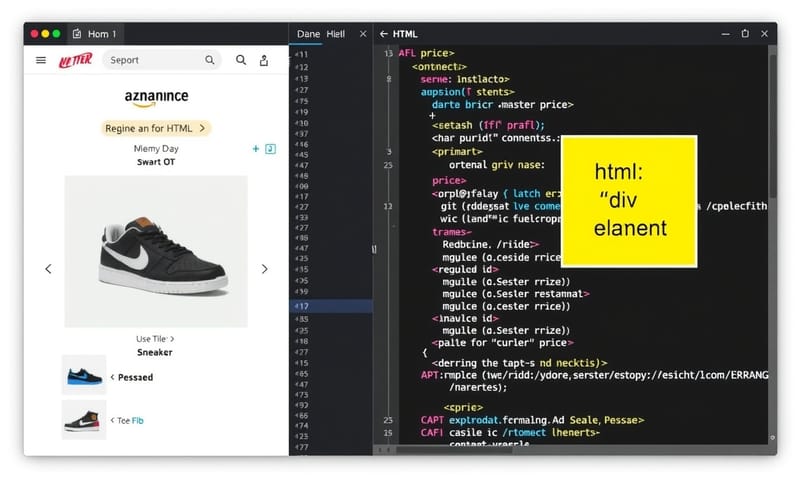
3. 網頁的地圖:HTML & CSS Selectors
爬蟲抓回來的 HTML 是一堆程式碼。 要從裡面精準拿出你要的資料,就要看懂這份「地圖」。HTML 建立了網頁的骨架,而 CSS Selectors 就像是地址系統,可以讓你精準定位到「價格在 `` 標籤底下,它的 class 是 `price-tag`」這樣的元素,然後把裡面的數字拿出來。
4. 會動的目標:動態網站 (Dynamic Website)
很多現代網站是用 JavaScript 動態載入內容的。 也就是說,你一開始拿到的 HTML 原始碼可能是個空殼,真正的內容是在你的瀏覽器執行了 JavaScript 之後才跑出來的。這種網站對基本爬蟲來說就很頭痛,因為它只會看第一時間拿到的 HTML,看不到後來才出現的內容。要解決這個問題,通常需要用 Selenium 或類似的工具,去模擬一個真正的瀏覽器來載入頁面,等內容都跑出來再抓。
5. 最重要的事:法律與道德
技術上能抓,不代表你可以抓。這是最重要也最容易出事的地方。爬蟲本身技術中立,但用途可能違法。
- 服務條款 (ToS):幾乎所有網站都有服務條款,裡面很可能寫了禁止自動化抓取。違反了雖然不一定犯法,但可能構成違約。
- 著作權:網站上的文章、圖片、影片,只要有原創性,就受著作權保護。你把人家辛苦寫的文章整篇抓去自己網站貼,就是侵犯「重製權」。
- 個資:如果抓取的資料包含姓名、聯絡方式等可以識別到個人的資訊,就要非常小心。 這邊就牽涉到不同地區的法規了。
- 歐洲的 GDPR:在歐盟,規定非常嚴格。他們認為,即使是公開資料,只要是個人資料,處理(包含蒐集)就必須有明確的法律基礎,例如當事人同意,但這在爬蟲情境下幾乎不可能做到。 所以很多觀點認為,在 GDPR 下,大部分的網路爬取都處於違法邊緣。
- 台灣的個資法:在台灣,主要看《個人資料保護法》。對於「當事人自行公開或其他已合法公開之個人資料」,在符合蒐集目的的前提下,是可以蒐集處理的。 但這條界線其實很模糊。最近台灣就有一個知名案例(Lawsnote 案),一家法律科技公司爬取了另一家公司的法律資料庫,結果被法院認定妨礙電腦使用與侵害編輯著作權,判了重刑跟高額賠償。 這案子引起很大爭議,顯示出在台灣,即使是爬取看似公開的資料,只要用於商業競爭,仍有極高的法律風險。
- 對伺服器造成負擔:如果你為了快,用超高頻率去抓一個網站,導致對方網站變慢甚至掛掉,這可能構成《刑法》的「妨害電腦使用罪」。

為什麼我的爬蟲跑不動?(常見的坑)
寫了爬蟲,卻發現一下就掛了?很正常。現在網站都有各種「反爬蟲」機制。
- IP 被封鎖:短時間內同一個 IP 位址發出太多請求,網站防火牆會覺得你是攻擊,直接把你的 IP 封鎖。
- 驗證碼 (CAPTCHA):「我不是機器人」的勾選、點選紅綠燈圖片...這些都是用來擋機器人的。
- 使用者代理 (User-Agent) 檢查:網站會檢查發出請求的是普通瀏覽器還是爬蟲程式。很多爬蟲程式會忘了偽裝成瀏覽器,馬上被識破。
- 蜜罐 (Honeypot):網站故意放一些人眼看不到但爬蟲會點進去的隱藏連結,你一點進去,網站就知道你是爬蟲,直接封鎖。
- 網站版面變更:你的爬蟲是照著固定版面結構去抓資料的。只要網站一改版,你寫的規則就全亂了,程式直接報錯。
常見錯誤與修正
剛開始寫爬蟲,很容易犯一些「沒禮貌」的錯。不只會被擋,也給網站管理者帶來困擾。
| 常見錯誤 | 為什麼這樣不好? | 有禮貌的作法 |
|---|---|---|
| 抓太快 | 你把人家網站當自己家硬碟在操啊!會造成伺服器沉重負擔,甚至當機。 | 拜託睡一下!在每個請求之間加上幾秒的延遲 (`time.sleep()`)。 |
| 不看 `robots.txt` | 這等於是無視主人貼在門口的「請勿進入」。非常不尊重。 | 先讀 `robots.txt`,乖乖遵守規則,不該爬的地方就別去。 |
| 從不偽裝 User-Agent | 等於在額頭上貼著「我是爬蟲」。有些網站會直接擋掉非瀏覽器的請求。 | 假裝自己是個正常的瀏覽器。在請求的 Header 裡加上 `User-Agent` 資訊。 |
| 拿到資料就跑 | 你抓的資料很可能是別人有著作權的心血結晶,或是包含敏感個資。 | 思考資料的合法性。 只是個人學習用?還是要商業用途?有沒有個資? 風險完全不同。 |
總之,寫爬蟲就像去別人家作客,保持禮貌、遵守規矩,才能當個受歡迎的客人,而不是被掃地出門的惡棍。
你呢?如果給你一個爬蟲程式,你第一個想抓什麼樣的資料來分析?是分析股票趨勢,還是看看 PTT 鄉民都在討論什麼?在下面留言分享你的想法吧!




