
欸,我最近在想一件事喔,就是我們現在用這些 App 啊、網站啊,都覺得理所當然。Netflix 按了就播,蝦皮下單秒速成立,LINE 訊息傳過去對方就收到了。好像一切都...嗯...絲滑般順暢?
但說真的,這背後根本不是魔法。每一個「順暢」的體驗,底下都藏著一堆工程師們的角力跟痛苦的決定。系統設計這玩意,真的不是畫畫框框、拉拉箭頭那麼簡單,它更像是一種...一種平衡的藝術,你常常得在兩個都超重要的東西之間選一個。想要系統隨時都在線?那你可能得犧牲一點點資料的即時性。想要反應時間快到毫秒等級?那...你可能就沒辦法一次處理所有事情。
這些選擇都不是空談,它們直接決定了我們每天在用的東西跑起來是什麼樣子。今天,我想來聊聊這些藏在背後的「權衡取捨」。我把它們分成三大類,這樣比較好懂。這不是什麼教科書,比較像是我自己消化後的筆記,順便跟你分享一下。
資料一致性的大哉問:又要快又要對,可能嗎?
嗯...這部分最繞,但也最核心。所有跟「資料」有關的系統,都逃不掉這個問題。簡單講,就是當你的使用者、你的資料遍佈全世界的時候,你要怎麼確保大家看到的都是同一樣東西?
這一切,幾乎都跟一個叫 CAP 定理 的東西有關。它說在一個分散式系統裡,三個願望(資料一致性 Consistency、服務可用性 Availability、網路分區容錯性 Partition tolerance)你最多只能實現兩個。網路問題(P)是一定會發生的,所以你只能在 C 跟 A 之間選。要嘛保證資料絕對正確(C),但系統可能暫時不能用;要嘛保證系統隨時能用(A),但資料可能暫時有點不同步。
我自己是覺得,這就衍生出好幾個經典的二選一難題。

第一個就是所謂的「擴展性 vs. 一致性」。你要服務幾百萬人(高擴展性),資料就得分散在世界各地的機器上。但機器越多,要讓每一台的資料都同步,就越難。你看 Twitter 就是個例子,為了讓系統在全球都能順順地跑,他們選了所謂的「最終一致性模型」。意思就是,你發了一篇文,你紐約的朋友可能要過個零點幾秒才看到,不會是「同時」。但好處是,整個推特不會因為瞬間流量太大就掛掉。犧牲一點點即時性,換來整個平台的穩定。
這就直接連到下一個問題:「強一致性 vs. 最終一致性」。
強一致性,就是銀行系統在用的那種。你轉帳一萬塊,餘額少一萬,對方帳戶多一萬,這件事必須是個「原子操作」,全國、全世界的 ATM 查到的都得是這個結果,一秒都不能差。但為了做到這點,系統的延遲會變高,因為要等所有地方都確認好了才行。
反過來說,電商系統就很愛用「最終一致性」。Amazon 的核心資料庫 DynamoDB 就是這樣設計的。你想想看,黑色星期五那天,幾千萬人同時在搶東西,如果每下一筆訂單,系統都要龜毛地等到全球所有備份資料庫都說「OK,庫存已扣!」,那網站早就卡死了。所以 Amazon 的策略是,先讓你下單成功,系統先回你「買到了!」,然後再慢慢去同步各地的庫存資料。這可能會造成...嗯...極少數情況下,你買到最後一件商品,但其實前一秒已經被別人買走了。但這個小風險,換來的是整個購物車系統在超大流量下依然堅挺。說真的,這點跟我們在台灣看到的情況很不一樣,台灣很多電商平台剛起步時,可能還是習慣傳統關聯式資料庫那種強一致性,因為老闆會覺得訂單跟庫存一塊錢都不能錯。但當規模大到像 momo 或 PChome 那樣,他們肯定也得面對類似的取捨。
那...要做到這種彈性,工具也要跟著換。所以就有了「SQL vs. NoSQL」的戰爭。SQL 資料庫,像 MySQL,結構很嚴謹,像個管理超好的圖書館,查資料很方便,但你要改分類或擴建就很麻煩。NoSQL 呢,像 MongoDB 或臉書訊息在用的 Apache HBase,它就像一塊超大的白板,你想怎麼寫就怎麼寫,擴充超容易,但缺點就是沒人幫你管秩序,資料的一致性得靠你自己寫程式去保證。Facebook Messenger 就是為了應付幾十億人的訊息量,才從 SQL 跳到 NoSQL 的,他們要的是極致的寫入速度和擴展性,而不是銀行等級的交易保證。
速度與效率的拉扯戰:怎樣才算「快」?
OK,搞定資料怎麼存之後,下一個問題就是,怎麼讓使用者覺得「快」?但「快」其實有兩種定義,這就是個有趣的拉扯了。
第一種快,叫「低延遲 (Latency)」。就是你一提出要求,系統多久給你回應。你按讚,那個愛心馬上亮起來,這就是低延遲。第二種快,叫「高吞吐量 (Throughput)」。指的是系統一秒鐘能處理多少個要求。這就像高速公路的收費站,開的閘口越多,一小時能過的車就越多。
問題來了,這兩個通常是打架的。你如果要讓每個要求都超快回應(低延遲),可能就得給它專用通道,結果就是能同時服務的人變少(低吞吐量)。反過來,你如果要一次服務超多人(高吞吐量),那大家可能都要排一下隊,每個人的等待時間(延遲)就會增加。
Netflix 就是一個極度重視「低延遲」的公司。你想想,你窩在沙發上要追劇,按下播放鍵,結果還要轉個十秒的圈圈,你大概會想砸電視吧?所以 Netflix 用盡各種方法,像是把影片快取到離你家最近的伺服器(CDN),還有把各種功能拆開(微服務),來確保你按下去的那個瞬間,影片就得給我播出來。至於背景那些數據分析啊、用戶行為記錄啊,那些東西晚一點再處理沒關係,可以整批做,不用即時。對他們來說,用戶「感覺到」的速度,比系統後台的處理總量更重要。
說到這個「晚點再處理」,就帶到了「批次處理 vs. 串流處理」。
- 批次處理 (Batch):就像麵包店每天凌晨烤好一天的麵包,早上一次上架。它適合處理超大量的、非即時的資料。例如,公司月底結算財報、網站每天半夜分析使用者 log。效率高,但有延遲。
- 串流處理 (Stream):就像手搖飲店,一個客人點單,就馬上做一杯。它處理的是持續不斷流入的資料,追求即時反應。例如,信用卡盜刷偵測、股票即時報價。
很多大公司其實是兩者都用。 опять, 拿 Netflix 來說,他們用批次處理來分析你幾個月來的觀看紀錄,然後算出你可能會喜歡哪一種類型的電影,這是他們推薦系統的大腦。但同時,他們也用串流處理來偵測你現在是不是網路卡頓了、要不要幫你降低一點畫質,或是你剛看完一部片,首頁要不要馬上推個相關的給你。一個管長期策略,一個管即時反應。
而要讓這一切體驗更順,最後的魔法就是「快取 (Caching)」。快取有很多種策略,其中一個有趣的選擇是「Read-Through vs. Write-Through」。
- Read-Through (讀取時穿透):App 先問快取「有資料嗎?」,快取說「沒有」,然後快取自己跑去問資料庫,拿回答案後,存一份自己這裡,再把答案給 App。好處是懶人包,App 不用管資料庫。壞處是第一次讀取的人會覺得「怎麼慢半拍」。
- Write-Through (寫入時穿透):App 要更新資料時,會「同時」寫入快取和資料庫。好處是能確保快取裡的資料永遠都是最新的。壞處就是...寫入速度會變慢,因為要等兩邊都OK才算完成。
Twitter 的時間軸就是個例子。他們非常需要「新鮮度」,你不想刷了半天看到的都是舊推文吧?所以他們比較偏向 Write-Through 的概念。當有人發文,這個動作會立刻更新到快取層,這樣他的追隨者一刷新,就能馬上看到新東西。對社群媒體來說,這種即時互動感,值得用那一點點寫入延遲來交換。
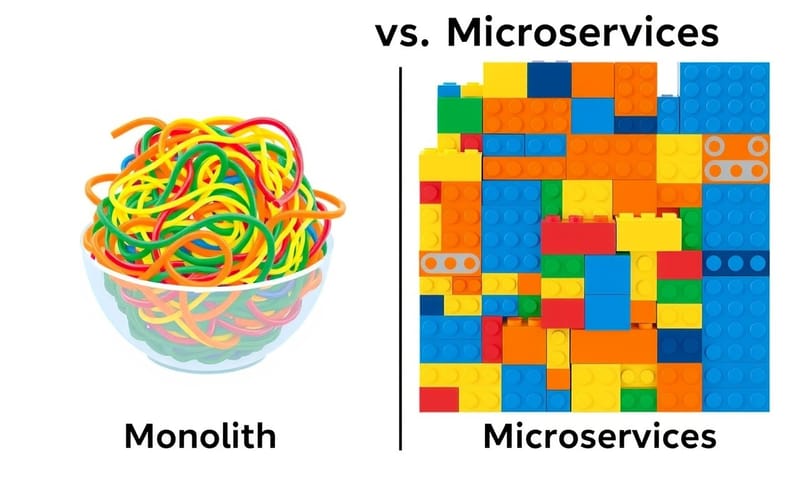
架構的十字路口:蓋大樓還是組合屋?
最後這組權衡,是更高層次的,關於你整個系統的「骨架」要怎麼搭。這通常是專案一開始就要做的重大決定。
最有名的,大概就是「單體式架構 vs. 微服務架構」了。
單體 (Monolith) 就像一棟什麼機能都有的超級大樓,食衣住行育樂全包了。一開始蓋起來很方便,大家都在同一個地方工作。但久了之後,你要改裝其中一個小角落,比如把餐廳擴大,可能就要動到整棟樓的管線,超麻煩。而且如果餐廳的廚房失火,可能整棟大樓都要疏散。
微服務 (Microservices) 就不一樣了,它像一個社區,裡面有很多獨立的房子。一棟是餐廳、一棟是電影院、一棟是健身房。每棟房子可以獨立蓋、獨立裝潢、獨立擴建。餐廳要擴建,不會影響到隔壁電影院。但缺點就是...管理整個社區很花心力,房子之間的交通(API 呼叫)、水電(網路通訊)、安全(認證授權)都要規劃好,不然會亂成一團。
| 比較維度 | 單體式架構 (Monolith) | 微服務架構 (Microservices) |
|---|---|---|
| 開發速度 (初期) | 超快!所有東西都在一個專案裡,不用搞有的沒的通訊。 | 慢...光是設定環境、服務間溝通就夠你喝一壺了。 |
| 擴展性 | 很痛苦。A 功能流量大,結果得把整包程式複製好幾份,浪費資源。 | 超爽的。哪個服務忙不過來,就單獨加開那個服務的機器就好。 |
| 團隊合作 | 像在地獄裡打群架。幾十個人改同一份 code,互相踩來踩去。 | 可以切小隊。A 隊負責會員服務,B 隊負責訂單服務,互不干擾。 |
| 技術選項 | 一旦選了就沒回頭路。你用 Java 寫,就得一路 Java 到底。 | 很自由。A 服務用 Go,B 服務用 Python,只要 API 講得通就行。 |
| 維運複雜度 | 相對單純。就...顧好那一個大服務就好了。 | 根本是惡夢。幾十個、幾百個服務,掛了一個怎麼辦?監控、部署都是學問。 |
Uber 就是從單體走向微服務的血淋淋案例。一開始只有一個城市,一個 App,單體架構超棒。後來擴展到全世界,又加了 Uber Eats、動態計價...那個單體 App 簡直變成一個無法維護的巨獸。改個小功能,整個 App 都要重新測試部署,工程師苦不堪言。所以他們花了很大力氣,把它拆成幾千個微服務。雖然過程很痛,但也只有這樣,才能支撐他們現在這種全球規模的營運。
再來是「有狀態 vs. 無狀態 (Stateful vs. Stateless)」。這個比較抽象。想像一下,有狀態的服務就像你家巷口很熟的早餐店阿姨,她記得你「帥哥,一樣大冰奶、火腿蛋吐司不加美乃滋喔?」。她把你的「狀態」記在腦子裡了。無狀態的服務就像便利商店,你每次進去,店員都不認得你,你每次都要重新跟他說「我要一杯拿鐵、要...」。
無狀態的服務擴展起來特別容易,因為任何一台機器都能處理你的請求,反正它也不用記得你上次做了什麼。AWS 的 Lambda 雲端函式就是天生無狀態的。但這也代表,那個「記憶」的責任就丟給客戶端(你的瀏覽器或 App)了,你得自己拿著「號碼牌」(Token)去證明你是誰。有狀態的服務雖然對開發者比較直覺,但要擴展時,你就得煩惱怎麼讓所有機器都認識這位「帥哥」。
最後一個,開發 App 或網站時一定會碰到的,「REST vs. GraphQL」。這兩個都是 API 的設計風格。
REST API 像是餐廳的「套餐」。A 套餐就是主餐、沙拉、飲料,內容是固定的。你想要 A 套餐的主餐,配 B 套餐的飲料?不行。這就造成了「過度獲取」(我只想要主餐,你卻給我一整份套餐)或「多次請求」(我只好點 A、B 兩份套餐,再自己組合)的問題。
GraphQL 就不一樣了,它像是「自助餐」或「客製化點餐」。你拿著盤子,跟廚師說:「我要一塊牛排、兩顆花椰菜、一杯可樂」,廚師就精準地給你這些東西,不多也不少。這對手機 App 特別好,可以省下很多不必要的網路流量。GitHub 就是從 REST API 轉向提供 GraphQL API 的代表,讓開發者可以一次精準抓到他們要的專案資訊、Issue、PR,不用再像以前那樣發好幾個請求兜不攏。當然,對 GitHub 來說,要蓋一個這麼厲害的客製化廚房,後端的複雜度也高很多。
所以,到底該怎麼選?
看了這麼多,你可能頭都暈了。老實說,根本沒有「最好的」選擇,只有「最適合當下情境」的選擇。不過,還是有一些...嗯...可以參考的經驗法則啦。
如果你是個剛起步的新創公司,或是一個人開發的小專案,拜託,別想不開去搞微服務、NoSQL、串流處理。先用最簡單的單體式架構、配個你最熟的 SQL 資料庫(像 PostgreSQL)就對了。先把產品做出來驗證市場,比什麼都重要。先求有,再求好。
當你的使用者開始指數級成長,單體架構讓你改個東西就心驚膽跳,每次部署都要拜拜的時候...這就是考慮把核心、高流量的功能拆出來當微服務的時機了。當你的資料多到單一資料庫快爆炸,或是資料結構變來變去,那時候再來研究 NoSQL 也不遲。
說到底,這些技術和架構都只是工具。重點是搞清楚你「現在」要解決的「主要問題」是什麼。是開發速度?是千萬人同時上線的承載能力?還是資料的絕對正確性?釐清了這個,答案通常就呼之欲出了。
唉,系統設計就是這樣,永遠在走鋼索。你往左一步,可能犧牲了右邊的穩定;你往右一步,又可能失去了左邊的速度。這可能也是它...嗯...迷人的地方吧。就像人生一樣,你沒辦法什麼都要,對吧?




