
最近在想一個問題,如果我們要在記憶體(in-memory)裡頭做一個 Key-Value 資料庫,又要像 SQL 那樣有「交易(Transaction)」功能,這要怎麼搞?聽起來很單純,但真的做下去,會發現併發(Concurrency)跟交易這兩件事超級麻煩。
簡單說,就是要讓系統在很多人同時存取的時候,既不會慢得要死,又能保證資料不會亂掉。這真的很需要一點技巧。
所以,為什麼 Transaction 這麼重要?
你知道嗎,大部分的資料庫都會說自己是「併發安全(concurrent-safe)」,意思就是很多人同時用不會把資料搞爛。但這不代表它們都支援「交易(transaction)」。
這兩者差在哪?併發安全只是保證單一操作不會出錯。但 Transaction 保證的是「一系列操作」要嘛全部成功,要嘛全部失敗,不會有做一半的狀況。這就是所謂的「原子性(atomicity)」。
我猜很多人第一個會想到 Redis。Redis 確實有用 `MULTI` 和 `EXEC` 來做 transaction,但老實說,它的 transaction 有點...嗯,不夠力。
比方說你看這段:
MULTI
SET key1 "value1"
INCR key2 // 假設 key2 存的不是數字,這行會失敗
SET key3 "value3"
EXEC在 Redis 裡,就算中間的 `INCR key2` 因為格式不對而失敗了,它還是會繼續執行 `SET key3 "value3"`。結果就是資料處在一個很奇怪的中間狀態。它沒有自動回復(rollback)的機制。這在高要求的情境下,其實是個大問題。
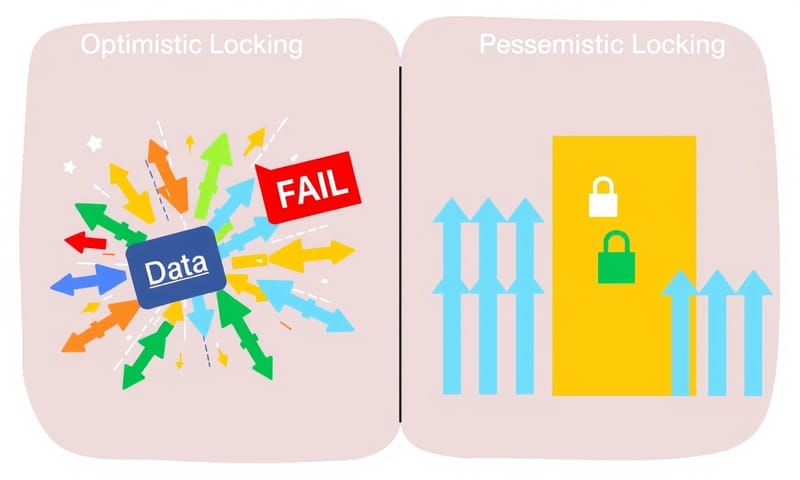
樂觀鎖 vs 悲觀鎖,選哪邊?
為了解決這個問題,Redis 提供了 `WATCH` 這個指令,這是一種「樂觀鎖 (Optimistic Locking)」。它的想法很天真,就是「我猜應該不會有人跟我搶吧?」
它會在交易開始前「監視」某個 key,如果在執行 `EXEC` 之前,這個 key 被別人改掉了,整個交易就會失敗。聽起來不錯,但在高併發、大家搶著改同一個東西的場景...這根本是災難。你會看到一堆交易不斷失敗、不斷重試,系統變得極度不穩定。
所以,我自己是覺得,與其那麼樂觀,不如悲觀一點。這就是「悲觀鎖 (Pessimistic Locking)」。它的想法是「我猜一定會有人跟我搶」,所以它會在動手改資料之前,先把要用的資源全部鎖起來。別人想動?抱歉,請排隊。
我們來直接比較一下這兩種鎖的感覺:
| 鎖的類型 | 核心思想 | 適合場景 | 缺點 |
|---|---|---|---|
| 樂觀鎖 (Optimistic Locking) | 先做再說,提交時才檢查有沒有衝突。很像大家一起衝,到終點才看誰犯規。 | 衝突很少發生的地方。例如,大家都在讀資料,偶爾才有人寫入。 | 在高併發、高衝突的環境下,會一直失敗重試,搞死人。 |
| 悲觀鎖 (Pessimistic Locking) | 先鎖再說,確保在我用完之前,沒人能碰。像是在廁所門上掛「使用中」。 | 衝突很頻繁的場景。例如,秒殺活動搶庫存,大家都要改同一個數字。 | 因為要等鎖,效能可能會差一點,而且如果鎖設計不好,容易卡死(deadlock)。 |
在高流量系統裡,依賴樂觀鎖的重試機制會讓錯誤處理變得超複雜。所以,這次我決定自己動手,用 Go 來實作一個支援悲觀鎖、類似 SQL 風格的交易機制的 in-memory store。
怎麼做:一步一步來
好,那我們來拆解一下整個實作過程。這不是一個簡單的東西,得分好幾步走。
第一步:先有個併發安全的 Map
在 Go 裡面,第一個想到的 Key-Value 結構就是 `map[K]V`。但...千萬記得,Go 內建的 map 不是併發安全的。如果你在不同的 goroutine 同時讀寫它,程式會直接 panic 給你看。
Go 官方有提供 `sync.Map`,這東西是併發安全的。不過,考慮到後面要加上複雜的交易邏輯,我不確定它好不好操作。所以為了彈性,我決定用更底層的 `sync.RWMutex` (讀寫鎖) 來自己包一個。
為什麼用 `RWMutex` 而不是 `Mutex`?因為 `RWMutex` 效能更好。它允許多個「讀取者」同時進入,但「寫入者」一次只能有一個。而 `Mutex` 不管讀寫,一次都只能一個進去。對於讀多寫少的場景,`RWMutex` 的優勢很明顯。
基礎結構大概長這樣:
import "sync"
type Database[K comparable, V any] struct {
mu sync.RWMutex
data map[K]V
}
// ... Get 和 Set 方法 ...這樣我們就有了一個基本的、併發安全的底層儲存了。
第二步:實現 Per-Key 鎖定
交易的時候,我們總不能把整個資料庫都鎖住吧?那樣效率太低了。理想情況是,我這次交易要動到 `key1` 跟 `key2`,那我就只鎖這兩個 key,其他人要動 `key3` 還是可以動。
這就需要一個「Per-Key Lock」的機制。我們需要在 `Database` 結構裡多加一個 map 來專門存放每個 key 對應的鎖。
type Database[K comparable, V any] struct {
dataMu sync.RWMutex // 保護 data map
data map[K]V
lockMu sync.RWMutex // 保護 locks map
locks map[K]*sync.Mutex
}這裡有兩個鎖,`dataMu` 是管 `data` 這個 map 的,`lockMu` 是管 `locks` 這個 map 的。為什麼連鎖的 map 也要保護?因為可能同時有好幾個 goroutine 要來拿鎖,它們可能會同時去修改 `locks` 這個 map(比如新增一個鎖),所以也需要保護。
接下來是 `getLock` 函式的演進,這蠻有趣的。一開始最直覺的寫法是:
// 第一次嘗試:簡單但效能差
func (db *Database[K, V]) getLock(key K) *sync.Mutex {
db.lockMu.Lock() // 直接上寫鎖
defer db.lockMu.Unlock()
if _, exists := db.locks[key]; !exists {
db.locks[key] = &sync.Mutex{}
}
return db.locks[key]
}這寫法很簡單,但 `db.lockMu.Lock()` 會把所有想拿鎖的 goroutine 都卡住,即使它們只是想拿一個已經存在的鎖。效能不好。
所以改良版是這樣,這也是所謂的 "read-optimized" 策略:
// 第二次嘗試:讀取優化
func (db *Database[K, V]) getLock(key K) *sync.Mutex {
db.lockMu.RLock() // 先用讀鎖,讓大家都可以進來查
lock, exists := db.locks[key]
if exists {
defer db.lockMu.RUnlock()
return lock // 鎖存在,直接回傳
}
// 鎖不存在,才需要進入寫入模式
db.lockMu.RUnlock() // 釋放讀鎖
db.lockMu.Lock() // 升級成寫鎖
defer db.lockMu.Unlock()
// Double check,因為可能在你等寫鎖的時候,別人已經建好了
if lock, exists := db.locks[key]; exists {
return lock
}
// 真的沒有,才建立新的鎖
lock = &sync.Mutex{}
db.locks[key] = lock
return lock
}這段程式碼的邏輯就細膩多了。它先用比較輕量的讀鎖 (`RLock`) 去檢查,大部分情況下鎖都已經存在,這樣就可以很快回傳。只有在鎖真的不存在時,才需要去搶那個比較重的寫鎖 (`Lock`) 來建立新鎖。這個小優化在高併發時差很多。

第三步:打造 SQL-Like 的 Transaction
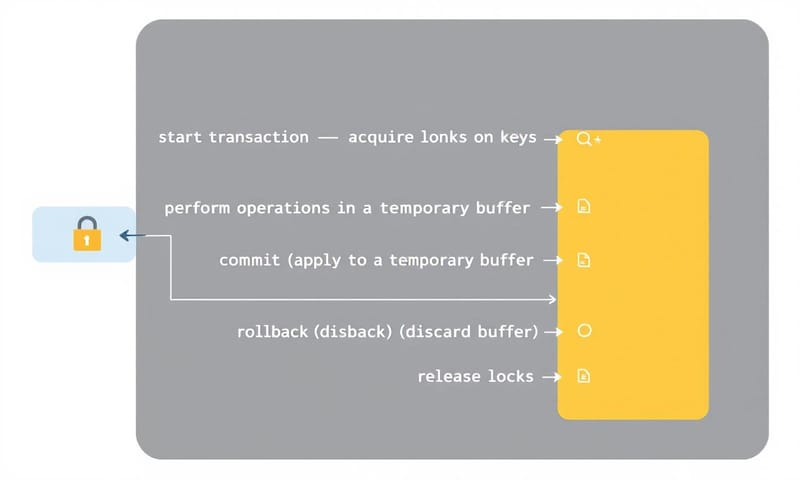
有了底層的鎖,終於可以來組裝我們的 Transaction 了。一個完整的交易流程大概是:
- 啟動交易:告訴系統我要動哪些 key,然後把這些 key 都鎖起來。同時,建立一個「暫存區」。
- 執行操作:在交易中做的所有讀寫,都只針對這個「暫存區」,完全不碰真實的資料庫。
- 結束交易:要嘛 `Commit`(把暫存區的修改一次性寫回真實資料庫),要嘛 `Rollback`(直接把暫存區丟掉,當作什麼事都沒發生)。然後把鎖解開。
核心概念就是「延遲修改」和「隔離」。所有變動都先在自己的小空間裡搞定,最後才決定要不要同步到大世界。
交易開始時,我們會把要用到的 key 先鎖起來,並把它們的原始值複製一份到交易的暫存 `temp` map 裡。之後的 `Get` 和 `Set` 都只跟這個 `temp` 互動。
`Commit` 的時候,就是把 `temp` 裡面的資料倒回 `db.data`。`Rollback` 更簡單,因為我們從頭到尾都沒動過 `db.data`,所以 Rollback 基本上只要把鎖解開就行了,暫存區的資料會被 Go 的垃圾回收機制收走。
啊對了,千萬小心死結 (Deadlock)!
這是一個非常、非常重要的點。當你使用多個鎖的時候,死結(Deadlock)就像個幽靈一樣,隨時可能出現。
想像一下這個情境:
- 交易 A:想鎖住 `key1`,再鎖住 `key2`。
- 交易 B:想鎖住 `key2`,再鎖住 `key1`。
如果 A 成功鎖了 `key1`,同時 B 成功鎖了 `key2`。接下來,A 要等 B 釋放 `key2`,B 要等 A 釋放 `key1`...然後...就沒有然後了,兩個交易互相卡死,直到天荒地老。
怎麼解決?最簡單暴力的方法就是:規定鎖的順序。
在我們的 `StartTransaction` 函式裡,有一段不起眼但至關重要的程式碼:
// Sort & remove duplicates to prevent deadlock
slices.Sort(keys)
keys = slices.Compact(keys)
for _, key := range keys {
// ... lock key
}在鎖定之前,先把所有要鎖的 key 進行排序(比如按字母順序)。這樣不管交易 A (`key1`, `key2`) 還是交易 B (`key2`, `key1`),進來之後都會被排序成 (`key1`, `key2`)。大家都按照同一個順序去拿鎖,就不會發生你等我、我等你的死結情況了。
這個小技巧在處理併發鎖的時候,真的是救命稻草。
所以,這樣做值得嗎?
說真的,自己從頭刻一個具備交易功能的 in-memory store,比直接用現成的方案(比如 Redis)要麻煩得多。你需要考慮很多細節,像是鎖的粒度、效能優化、還有可怕的死結問題。
不過呢,換來的好處是完全的可控性和可預期的行為。在某些對資料一致性要求極高、而且併發衝突很常見的場景(像是金融交易、搶票系統),這種「悲觀但可靠」的模式,反而能提供比樂觀鎖更穩定的表現。
它不是萬靈丹,但絕對是工具箱裡一個很強大的選項。這整個過程,我自己是覺得學到蠻多的。
那你覺得呢?在什麼樣的場景下,你會選擇自己手刻這種悲觀鎖交易,而不是用 Redis 那樣的樂觀鎖機制?在下面留言聊聊你的看法吧!




